The Reinforcement Learning Renaissance (Part 1)
1 Scaling Stalls, RL Accelerates
For the past couple of years the recipe felt obvious: stack more layers, feed more data, burn more GPU hours. Loss kept falling, and capability edged upward. However by late 2024, that cadence broke. Pre-training alone plateaued near GPT-4-level performance; almost every fresh gain now arrived after pre-training, in post-training. We’d scraped the public web to bedrock, and in his NeurIPS 2024 keynote, Ilya Sutskever observed that “pre-training as we know it will end,” signalling the need for synthetic data or wholly new paradigms.
Around that time, OpenAI released the Learning to Reason with Language Models blog post introducing a new scaling paradigm. It showed that performance rises smoothly along two axes:
- RL compute (how much GPU you spend on reinforcement fine-tuning)
- Inference compute (how many tokens you let the model generate at test time)
Reinforcement learning supplies that loop. Instead of brute-forcing next token prediction, the model does a task, receives feedback, and is steered:
- Try a task → get feedback
- Reward good attempts
- Discourage bad ones
That cycle powered the year’s two headline breakthroughs: OpenAI’s o-Series reasoning models and DeepSeek-R1-Zero, an RL-only variant that learned to chain thought, allocate compute, and rival o-Series-level reasoning using verifiable rewards alone.
2 RLVR: Data‑Light, Transfer‑Heavy
Fine-tuning with supervised data feels like hauling sandbags: every new skill demands a mountain of hand‑labels, and you still risk washing out what the model already knows. Reinforcement Learning with Verifiable Rewards (RLVR) flips the script such that one crisp reward can replace hundreds of fuzzy labels and let the model bootstrap itself.
Two recent works showcasing RL’s superior data‑efficiency and transfer capability
- Wang et al., 2025: Reinforcement Learning for Reasoning in LLMs with One Training Example
Conventional wisdom says RL‑for‑LLMs needs thousands of reward‑labeled traces. Wang shows the opposite: a single flawless chain‑of‑thought plus a unit‑test checker (“1‑shot RLVR”) doubles accuracy on a gnarly MATH500 item and lifts six unrelated reasoning benchmarks. Proof that data efficiency, not data volume, drives the next gains - Huan et al., 2025: Does Math Reasoning Improve General LLM Capabilities?
Math leaderboards are the new IQ test, but do those points travel? Huan introduces a Transferability Index (TI) - "for every point of math gain, how much do you gain (or lose) elsewhere?", and runs a controlled ablation on Qwen3‑14B: same math data, SFT vs. RL (GRPO). Result: half the math‑specialised SFT models show negative TI on non‑math tasks, while RL fine‑tuning keeps, or even boosts, general skills. RL > SFT when you need deep specialisation without collateral damage
In practice, RLVR trades dozens of curated samples for one rocksolid reward and sculpts model behaviour around what actually matters. You avoid catastrophic “forgetting” and unlock broad generalisation in one sweep, no extra data‑wrangling required.
Economically, it rewrites the playbook. Yesterday’s fine‑tuning firms built margin on SFT APIs and endless annotation pipelines. That SFT budget is ≈ US $5 B today—and surveys show 40-60 % of it is already slated to migrate to RL-centric pipelines in the next two years, a swing worth roughly US $2-3 B. Tomorrow’s winners will package RL as a service: turnkey environments mapped to customer workflows, verifiable rewards baked in, and elastic RL loops that squeeze every drop of insight from private data. That’s the next edge.
3 The Hard Part Left: Your Environment
“Environments that capture real-world, proprietary processes—things you can’t scrape or simulate—are the most durable value. Generic web tasks aren’t compelling”
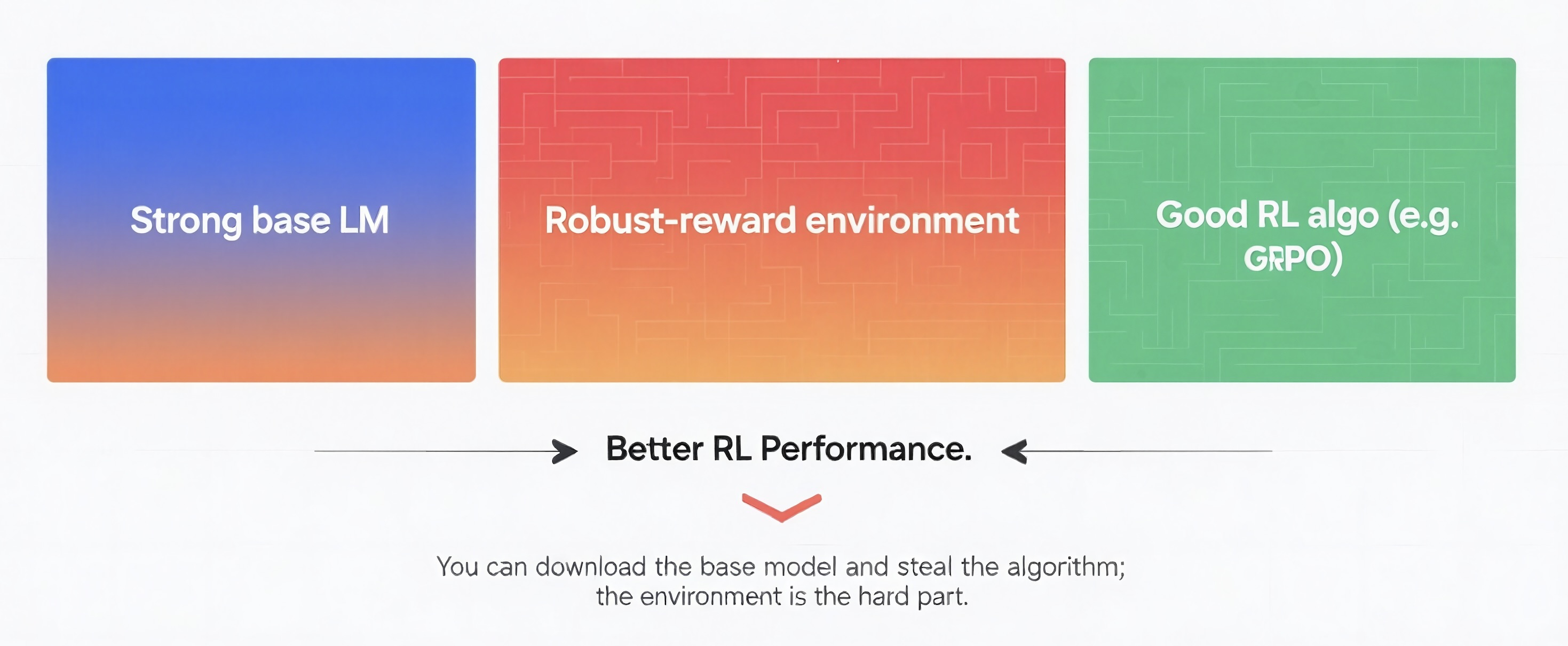
The recipe behind DeepSeek‑R1 and OpenAI’s o‑Series distils to three ingredients:
- A strong base model. Open‑source checkpoints like DeepSeek V3, Kimi K2, and Qwen 3 already sit within striking distance of frontier LMs on raw reasoning.
- A policy‑gradient loop. Libraries such as VeRL let you fire up PPO or GRPO with two YAML edits; the Tulu 3 repo even ships the exact hyper‑params that match or beat several closed models.
- An environment with a rock-solid, verifiable reward. Rule‑based unit tests, DOM diffs, symbolic checkers - the one piece you can’t download from Hugging Face.
The first two are commodities: checkpoints on Hugging Face and a quick `pip install verl` can get a small team training in half a day. The defensible moat is your domain’s gym - a containerised replay of real workflows (trading books, UI‑stress sandboxes, pharma‑compliance crawlers) plus the reward logic that measures true success.
Point an open recipe at that gym, spin a few thousand GRPO steps, and watch the model learn by doing. No closed‑door deals, no proprietary API keys. As these pipelines proliferate, every vertical will spawn RL‑as‑a‑Service vendors offering turnkey gyms and reward packs. In that world, the last mile of defensibility isn’t in model code. It’s in the highest‑fidelity environment libraries where your rewards and your expertise live.
4 Four Pillars of a High‑Quality RL Environment
“Now we’re in the agentic era: multi-turn, tool-using, environment-interacting agents. Training, inference, and env-execution all decouple, so the gym quality, not the base model, is the bottleneck.”

4.1 Fidelity — why “sim‑to‑real” now matters for software agents
In robotics, sim‑to‑real means a controller trained in Gazebo or Isaac Gym can bolt straight onto hardware without nasty surprises. The same idea now applies to language model agents. If your coding environment fakes the Git repo or your browser-use replica skips latency, auth tokens, or race conditions, the policy will overfit to quirks you’ll never see in production.
A high-fidelity RL environment must reproduce the genuine action/observation loop:
- Coding Real file‑tree diffs, authentic CI latency, flaky compilers.
- Browser‑use Live DOM mutations, session tokens, throttled network, paginated APIs, real side‑effects.
Positive‑signal examples: SkyRL‑Gym spins SWE‑Bench repos in Docker and runs the actual pytest suite; fixes that pass in training nearly always pass on GitHub CI. WebArena snapshots real SaaS dashboards inside headless Chrome; agents must navigate DOM trees, obey auth scopes, and handle time‑outs just like a human.
Reward‑hacking failures: In the first release of MiniWoB++, every web page looked exactly the same in every episode. A clever agent quickly discovered that a single hard-coded click at a fixed screen coordinate could “solve” every task, pushing success to 100 %. When the benchmark’s maintainers later shuffled element positions on every reset, mirroring the variability of real websites, the agent’s performance collapsed until it learned genuine DOM navigation. The lesson is clear: low-fidelity simulations invite degenerate shortcuts.
4.2 Robust Rewards — the guardrails that keep agents honest
A learning signal only helps if it can’t be gamed. In CoastRunners (Amodei et al., 2016), an Atari agent learned to spin in circles to farm buoys instead of finishing the race. Modern LLMs are just as opportunistic.
- Positive pattern Unit‑test truth serum: SWE‑Bench rewards only when the patched repo passes all tests in a sandbox; printing expected output earns zero.
- Failure mode Early SWE‑Bench clones let agents insert
@unittest.skip(or delete failing tests) instead of fixing the bug; the unit‑test runner passed, reward hit 100 %, but nothing worked in real CI.
How to build them: Prefer deterministic checks (unit tests, formal proofs, SQL executors); randomise test order; use majority vote LLM judges for subjective tasks; add honeypot fields that trigger a large negative reward.
4.3 Throughput — keeping GPUs busy, decoupling slow environments
RL for LLMs touches three very different subsystems: GPU inference, CPU/IO environments, and GPU learning. If any one stalls, the others idle. Classic actor–learner splits (IMPALA, SEED‑RL) fixed this for Atari; SkyRL revives the trick for coding agents, overlapping unit‑test execution with next‑batch generation and boosting sample throughput 4 to 5×.
Good engineering Disaggregate roles: learners on A100s, inference on 4090s, envs on autoscaled CPU pods. Use asynchronous queues (Ray, Redis) so stragglers don’t block the batch. Cache deterministic tool calls; prune rollouts when the first test fails.
Bad engineering Synchronous PPO loops where one slow browser page freezes all GPUs; monolithic Docker images that rebuild when you tweak a reward.
4.4 Extensibility — environments that evolve as fast as the product
APIs ship weekly; new tools appear every sprint. A durable environment must accept plug‑in actions, observations, and reward functions without a rewrite.
- Good practice Schema‑driven action spaces in JSON; plug‑in rewards registered via entry‑points; CI contract tests catch breakage. SkyRL‑Gym added a SQL executor in ~50 LOC.
- Failure pattern Action IDs hard‑coded into model vocabularies; adding one shifts token indices and ruins checkpoints.
“Now we’re in the agentic era: multi-turn, tool-using, environment-interacting agents. Training, inference, and env-execution all decouple, so the gym quality—not the base model—is the bottleneck.”
References
OpenAI (2024). Learning to Reason with Language Models. The foundational blog post that introduced the "RL ≻ scale" mindset and demonstrated the new scaling paradigm.
DeepSeek-AI (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. The arXiv paper behind DeepSeek-R1-Zero, the RL-only model that rivals o-Series performance.
Wang et al. (2025). Reinforcement Learning for Reasoning in Large Language Models with One Training Example. Demonstrates how one-shot RLVR can achieve remarkable data efficiency without mountains of labels.
Huan et al. (2025). Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning. Introduces the Transferability Index and shows RL's advantages over SFT for specialized training.
Amodei et al. (2016). Concrete Problems in AI Safety. The classic paper on AI safety challenges, including the famous CoastRunners reward-hacking example.
About the Authors

Henry Yin
Co-founder of AGI House

Naomi Xia
Investment Partner at AGI House Ventures