Native Multimodal Architectures: Why Cross-Modal Fusion Defines the Next Defensible Moat
Executive Summary
The multimodal inflection point has arrived. Our recent hackathon with Google and Graphon AI empowered 200+ builders to leverage the Gemini 3 launch and apply cross-modal reasoning, gesture-based interaction, and video understanding across a wide range of projects.
Our thesis on multimodality is defined on three core pillars:
Native architectures compound advantages. Companies building on native multimodal systems—like Figma, Vercel, and Luma AI—gain through synthetic data generation and architectural specialization. The critical question: does the value proposition improve or degrade as foundation models advance?
Embodied applications unlock highest-value use cases. World Labs, Mimic Robotics, and Physical Robotics demonstrate that deployment-scale embodied AI companies become data monopolies—generating proprietary multimodal datasets that web scraping cannot replicate.
Prosumer controllability drives sustainable revenue. Companies like Higgsfield AI and FishAudio achieve 10x better retention by optimizing for fine-grained creator control rather than consumer "magic."
We believe winners in this space will tackle the following: native architectural innovations, embodied applications with deployment traction, prosumer tools with demonstrated retention, and infrastructure plays reducing the complexity tax.
Part I: The Evolution to Native Multimodality
From Stitched Systems to Unified Intelligence
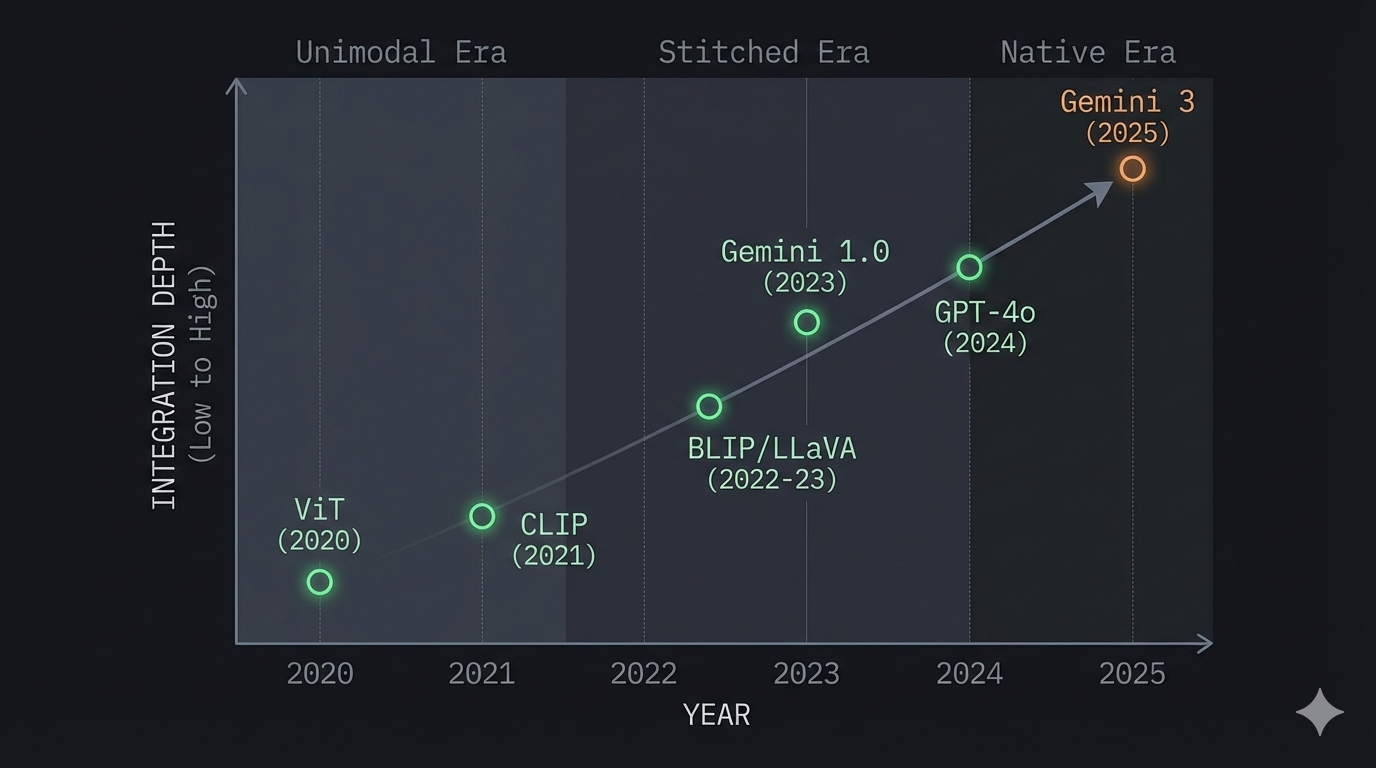
The release of Google's Gemini 3 on November 18, 2025 marked a threshold moment: the first frontier model to achieve state-of-the-art performance across reasoning, coding, and multimodal benchmarks simultaneously, trained end-to-end on interleaved text, images, audio, and video. This wasn't incremental progress—it was the culmination of a decade-long technical journey from "bolted together" multimodal systems to truly native architectures.
Understanding this evolution is essential for any investor in the space. The difference between native and stitched multimodality isn't just academic—it determines model capabilities, training efficiency, and ultimately which companies can compete at the frontier.
The Technical Foundation
Vision Transformers: Unifying Architecture Across Modalities (2020)
The Vision Transformer (ViT) demonstrated that images could be processed with the same fundamental mechanism as text: treat images as sequences of patches (typically 16x16 pixels), embed them as tokens, and run standard transformer attention. This was the first crack in the wall between vision and language architectures.
CLIP: The Cross-Modal Bridge (January 2021)
OpenAI's CLIP (Contrastive Language-Image Pre-training) was the critical conceptual breakthrough. The insight: train separate image and text encoders to map inputs into a shared embedding space, using contrastive learning to pull matching image-text pairs together while pushing mismatched pairs apart.
Key technical details:
- Dual-encoder architecture: ViT for images, transformer for text
- Trained on 400 million image-text pairs scraped from the internet
- Contrastive objective proved 4-10x more compute-efficient than generative alternatives
- Largest ViT model trained on 256 V100 GPUs for 12 days
CLIP enabled zero-shot image classification—describing a new object in plain English and having the model recognize it without any task-specific training. This was transformative, but still fundamentally a stitched approach: two separate encoders aligned post-hoc.
The Stitched Era: 2021–2023
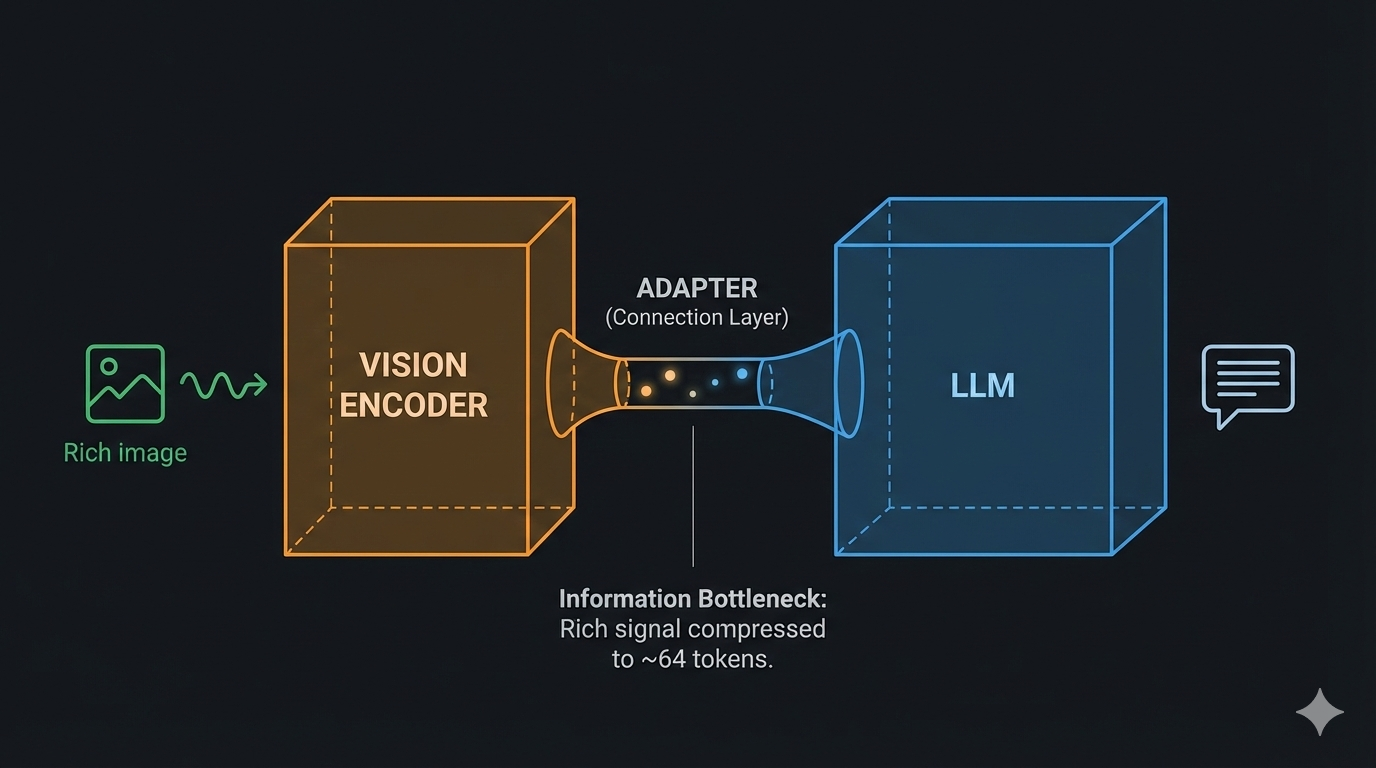
The years following CLIP saw an explosion of multimodal models, but they largely followed the same pattern: take a pre-trained language model, take a pre-trained vision encoder, and add an "adapter" or "bridge" module to connect them.
Examples of the stitched approach:
- BLIP/BLIP-2 (2022-2023): Added Q-Former modules to connect frozen vision encoders to frozen LLMs
- LLaVA (2023): Connected CLIP vision encoder to Vicuna LLM via simple linear projection
- GPT-4V (September 2023): Added vision capabilities to GPT-4 through integration layers
These models achieved impressive results but suffered from inherent limitations:
- Alignment gaps: Vision and language encoders were trained on different objectives with different data distributions
- Information bottlenecks: Adapter modules compressed visual information, leading to detail loss
- Modality competition: Models tended to "prefer" their language prior, especially as generation length increased
- Training inefficiency: Separate pre-training phases meant duplicated compute and missed cross-modal learning opportunities
The Native Multimodal Shift: 2023–2025
The performance differential on multimodal and reasoning benchmarks isn't coincidental—it's architectural.
Native advantages:
- Cross-modal attention throughout: In native models, visual tokens can attend to audio tokens, which can attend to text tokens, at every layer. Stitched models only achieve this at connection points.
- Unified representation learning: Native training creates embeddings where concepts exist across modalities. "A dog barking" as text, audio, and video all map to semantically coherent regions.
- No information bottleneck: Stitched models compress visual/audio information through adapter modules (often just 32-64 queries in Q-Former style architectures). Native models preserve full information flow.
- Better handling of ambiguity: When modalities provide conflicting signals, native models can resolve them through learned cross-modal relationships rather than heuristic fusion rules.
Major launches:
- Gemini 1.0 (December 2023): Google's original Gemini was the first major frontier model explicitly designed and trained from the ground up on text, images, audio, and video together.
- GPT-4o (May 2024): OpenAI's "omni" model unified text, image, and audio processing, achieving 232ms response times for voice—fast enough for natural conversation.
- Claude 3 Family (March 2024): Anthropic added strong vision capabilities, though the architecture remained more modular.
- LLaMA 3.2 Vision (September 2024): Meta released open-weight vision-language models, making multimodal capabilities accessible to the broader developer ecosystem.
- Gemini 2.0 (December 2024): Added two critical capabilities: native tool use and native generation. The model could invoke Google Search, execute code, and interact with external APIs as part of its reasoning process.
Gemini 3: The Native Multimodal Benchmark (November 2025)
Released just six days after OpenAI's GPT-5.1, Gemini 3 represents the maturation of native multimodal architecture. Where earlier models struggled to maintain performance across modalities, Gemini 3 demonstrates that unified training pays dividends:
Multimodal leadership across the board:
- MMMU-Pro: 81.0% (vs. 68% for stitched competitors)
- Video-MMMU: 87.6% (vs. 77.8% for Claude Sonnet 4.5)
- ScreenSpot-Pro: 72.7% (vs. 36.2% for Claude, 3.5% for GPT-5.1)
The performance gap on ScreenSpot-Pro is particularly revealing: understanding UI screenshots requires synthesizing spatial layout, text, icons, and contextual relationships—exactly the kind of cross-modal reasoning that native architectures excel at.
Deep Think: Extended Reasoning for Multimodal Problems
Gemini 3's "Deep Think" mode extends reasoning chains to 10-15 coherent steps (vs. 5-6 in previous models), particularly valuable for multimodal tasks. On ARC-AGI-2—a benchmark designed to test genuine visual reasoning rather than memorization—Deep Think achieved 45.1%, nearly triple the performance of models without extended reasoning capabilities.
Combined with its 1M token context window, Gemini 3 can reason over hours of video, thousands of images, or entire document repositories while maintaining cross-modal coherence.
Part II: The Current Frontier Model Landscape
| Model | Company | Launch Date | Key Strengths | Notable Benchmarks |
|---|---|---|---|---|
| Claude Sonnet 4.5 | Anthropic | Sept. 29, 2025 | Best coding model, agentic reliability | SWE-bench: 77.2%, MMMU: 77.8% |
| GPT-5.1 | OpenAI | Nov. 12, 2025 | Adaptive reasoning, speed optimization | MMMU: 84.2%, Video-MMMU: 80.4% |
| Gemini 3 | Nov. 18, 2025 | Multimodal reasoning, Deep Think, ecosystem integration | MMMU-Pro: 81.0%, Video-MMMU: 87.6%, ScreenSpot-Pro: 72.7% | |
| Claude Opus 4.5 | Anthropic | Nov. 24, 2025 | Practical coding leadership, agentic reliability | SWE-bench: 80.9%, OSWorld: 66.3% |
| GPT-5.2 | OpenAI | Dec. 11, 2025 | Abstract reasoning, long-context performance | ARC-AGI-2: 52.9-54.2%, MMMU-Pro: 86.5%, Video-MMMU: 90.5% |

Part III: Investment Theses
Thesis 1: Native Multimodal Architectures Define the Next Competitive Moat
Core Assertion: Native multimodal architectures will capture disproportionate value over the next 24 months, while late-fusion approaches face commoditization as foundation models improve.
Evidence from Market Leaders
Figma's partnership as a Gemini launch partner for generative UI represents strategic positioning around native architectures. When Dylan Field's team demonstrated generating complete design systems from natural language at our hackathon, the key wasn't generation itself but coherence: color palettes maintaining accessibility ratios, component spacing following gestalt principles, and layout hierarchies preserving responsive behavior. This requires native architectural understanding of how visual semantics relate to functional requirements—something projection-layer approaches consistently fail to achieve.
Vercel's v0 product validates this pattern. Their "Prompt → Gemini → Next.js → Deploy" loops succeed not because they generate code (dozens of tools do that), but because they maintain React component coherence across iterations. When users request "make this form mobile-responsive and add validation," v0 understands semantic relationships between layout constraints, user input patterns, and error state management.
Luma AI's positioning as a "video-first AGI" company reflects founder Amit Jain's architectural conviction. Their focus on building video generation as a path to AGI, rather than treating video as a feature, signals belief in native multimodal training as the route to general intelligence. The technical rationale is sound: video contains dense supervisory signals about physics (gravity, momentum, collision), causality (temporal ordering, state transitions), and semantics (object permanence, scene composition).
The Synthetic Data Wedge
A critical implication: synthetic data generation becomes a viable moat when you control the architecture. Companies like Graphon AI can bypass hyperscaler data walls by generating cross-modal training pairs procedurally. When you design the architecture, you can create synthetic tasks targeting specific model weaknesses—generating physics simulations paired with video renders, or creating 3D scenes with ground-truth depth maps and multiple viewpoint projections.
Opportunity Characteristics:
- Architectural innovators building specialized native multimodal models for vertical domains where hyperscalers won't optimize
- Early integrators with privileged access to cutting-edge native architectures—launch partners like Figma, Framer, and Webflow
The critical question: Does this value proposition degrade or improve as foundation models advance? Late-fusion wrappers face commoditization risk. Native architecture plays compound their advantages.
Thesis 2: Embodied Applications Unlock Multimodality's Highest-Value Use Cases
Core Assertion: The killer application for multimodal AI isn't better chatbots or content generation—it's grounding intelligence in physical action through robotics and spatial computing, where cross-modal reasoning becomes economically essential rather than aesthetically nice-to-have.
Why Embodiment Solves the Grounding Problem
Fei-Fei Li's decision to found World Labs with focus on "Large World Models" for spatial intelligence represents a paradigm shift from her ImageNet legacy. Where ImageNet taught computers to recognize objects in images, World Labs aims to teach computers to understand 3D space, physics, and causality—prerequisites for embodied intelligence. This matters because embodied applications require verifiable correctness: factory robots that misunderstand depth relationships damage equipment; autonomous vehicles that fail to predict pedestrian trajectories cause accidents; surgical assistants that misinterpret force feedback harm patients.
The economic forcing function is crucial. In content generation, users tolerate hallucinations—an AI-generated marketing video with inconsistent physics is still useful. In embodied applications, hallucinations are catastrophic. This forces architectural rigor that ultimately produces more capable general-purpose models.
Market Validation
The Chinese embodied AI wave provides real-world validation. RoboParty's open-source bipedal platforms deliberately optimize for ecosystem building rather than hardware margins, mirroring the iPhone's playbook: provide low-cost platforms with strong multimodal datasets (vision + proprioception + force), and capture value through the developer community building applications.
European dexterity plays add another data point. Mimic Robotics focuses on "dexterous hands via human demonstration learning," with factory pilots at Fortune 500 manufacturers. The key technical insight is multimodal data fusion: force sensors provide haptic feedback while vision tracks object deformation, and models must learn policies satisfying both modalities simultaneously. This generates proprietary datasets that web scraping cannot replicate.
The Data Flywheel Advantage
Physical Robotics AS, founded by a 1X co-founder, exemplifies the data flywheel. Their focus on "force-sensitive robots for touch-based data collection" generates proprietary multimodal datasets that improve model performance. Each deployment produces paired (vision + force + audio) data for manipulation tasks, which trains better policies, which enables more deployments, which generates more data.
The implication: Embodied AI companies reaching deployment scale become data monopolies in their verticals. A warehouse robotics company with 10,000 deployed units generates millions of hours of (video + LiDAR + force + audio) data daily, creating model quality advantages that no amount of capital can overcome without equivalent physical access.
Opportunity Characteristics:
- Horizontal platforms building foundational spatial intelligence (World Labs) or data collection infrastructure (Physical Robotics, Mimic Robotics)
- Vertical specialists with proven pilot traction in high-value domains (manufacturing, logistics, healthcare)
Constraint: Robotics requires 2-5 year timelines from pilot to scale. For builders with appropriate time horizons, the moat depth at scale justifies the patience.
Thesis 3: Prosumer Controllability, Not Consumer Magic, Drives Sustainable Revenue
Core Assertion: Multimodal applications optimizing for fine-grained creator control and workflow integration achieve 10x better retention and monetization than consumer-focused "magic" experiences, because they become livelihood dependencies rather than entertainment novelties.
The Retention Divide
Higgsfield AI's founder Mahi de Silva articulated this clearly during Stanford multimodal panels: consumer AI apps targeting viral "wow" moments achieve <5% day-30 retention, while prosumer tools emphasizing "emotion controllability" and workflow integration achieve 40-70% retention. The difference isn't product quality—it's user dependency. A creator who learns to control FishAudio's emotion sliders (grief, joy, fear directions) for character voice acting embeds that tool into their income-generating workflow. Switching costs become prohibitive because relearning fine-grained controls represents lost productivity.
This explains Runway's pivot from consumer video generation to "storyboard-to-video pipelines with LLM reasoning" targeting professional creators. Their platform now supports prosumer features—shot-to-shot consistency controls, emotion direction, style transfer—enabling iterative refinement rather than one-shot generation.
"Ugly But Effective" Over Cinematic Perfection
Creatify AI's positioning as "AI video for advertising" demonstrates a counter-intuitive insight: data-optimized outputs beat aesthetic perfection. Their focus on generating "ugly but effective" ads—tested against conversion metrics rather than production values—captures B2B advertising spend more reliably than cinematic video generators. The multimodal advantage is specificity: text prompts define hooks and value propositions, image inputs establish brand guidelines, and the system optimizes outputs for click-through rates rather than visual appeal.
Workflow Integration as Competitive Advantage
Descript's multimodal editing agents integrate into existing creator workflows rather than replacing them. Their Overdub feature (text-based audio editing) and multimodal timeline (simultaneous audio/video/transcript editing) reduce friction for podcast creators who previously managed separate tools for recording, transcription, editing, and export. By owning the full workflow, Descript increases switching costs and captures usage data that improves their models.
Canva's evolution from design templates to AI content tools for SMB campaigns follows similar logic. Their multimodal workflow now generates copy + design + assets through agent orchestration, but the key is staying within Canva's environment. Users who start campaigns in Canva are more likely to finish there, even if individual AI components aren't best-in-class. Workflow gravity matters more than point solution superiority.
Opportunity Characteristics:
- Fine-grained controllability enabling iterative refinement (FishAudio's emotion sliders, Higgsfield's character animation controls)
- Workflow integration reducing tool-switching friction (Descript's multimodal editing, Canva's campaign orchestration)
- Data-driven optimization delivering ROI metrics over aesthetic quality (Creatify's ad conversion focus)
Cross-Cutting Theme: Infrastructure as the Enabling Layer
Across all three theses, a consistent pattern emerges: multimodal applications are infrastructure-limited today. Companies building picks-and-shovels for serving, data processing, and optimization capture value across the entire ecosystem while enabling application-layer innovation.
Fal.ai's rapid growth validates multimodal inference optimization as a standalone opportunity. Their efficient serving of mixed modalities (vision + text pipelines, audio + video processing) enables application builders to focus on product rather than infrastructure.
Pixeltable addresses what a16z's 2026 ideas highlight as "multimodal sludge"—the chaos of videos, PDFs, images, and logs that enterprise RAG systems must process reliably. Their approach of indexing and structuring this data for agent consumption reduces hallucinations and improves retrieval accuracy.
Edge deployment becomes critical as embodied applications and prosumer tools demand real-time performance (<100ms for robotics, <2s for interactive creation). Solutions for quantization, distillation, and caching of multimodal models on Qualcomm Snapdragon or Apple Silicon processors enable entire application categories that cloud-first approaches cannot support.
Part IV: Challenges and Opportunities for Builders
Challenge 1: The Context Length Ceiling for Long-Form Content
While text-based models comfortably handle 200K+ token contexts, multimodal contexts collapse far earlier. A 10-minute video at reasonable resolution consumes 50K-100K tokens even with aggressive compression. Add synchronized audio and a few reference images, and you've exhausted context budgets before meaningful reasoning begins.
Opportunities for builders:
- Hierarchical representations maintaining full fidelity for regions of interest while compressing background contextually
- Learned compression where models adapt token budgets dynamically based on content complexity
- Cross-modal redundancy elimination recognizing when audio narration and visual action convey identical information
Challenge 2: Real-Time Performance for Interactive Applications
Native multimodal models are computationally expensive. Gemini 3's Deep Think mode achieves breakthrough reasoning but requires seconds to minutes for complex queries. For embodied robotics needing <100ms perception-to-action loops, or prosumer creative tools targeting <2s iteration cycles, this latency is prohibitive.
Opportunities for builders:
- Speculative execution where lightweight models generate immediate responses while heavier models verify and refine in parallel
- Cached world models that pre-compute likely states and actions, enabling near-instant responses for high-probability scenarios
- Progressive refinement architectures providing usable outputs in 100ms, good outputs in 1s, excellent outputs in 10s
- Edge deployment enabling Gemini-quality reasoning on Qualcomm or Apple Silicon at interactive speeds
Challenge 3: Reliability and Verifiability in High-Stakes Domains
Multimodal models hallucinate in ways harder to detect than text-only systems. They generate plausible-sounding descriptions of images containing subtle factual errors, or maintain confident tones while misinterpreting spatial relationships. For robotics, medical diagnosis, or autonomous systems, these errors are catastrophic.
Opportunities for builders:
- Uncertainty quantification providing calibrated confidence scores—models should "know what they don't know"
- Grounding mechanisms tying model outputs to specific input regions (which pixels/audio segments/frames support this conclusion?)
- Consistency checks across multiple reasoning paths
Challenge 4: The Synthetic Data Quality Gap
While synthetic data generation bypasses web scraping limitations, most synthetic multimodal data lacks the complexity and edge cases found in real-world scenarios. Physics simulations produce clean, idealized interactions that don't transfer to messy reality.
Opportunities for builders:
- Adversarial synthesis generating inputs specifically designed to expose model weaknesses
- Hybrid approaches blending small amounts of expensive real-world data with large amounts of synthetic data intelligently
- Domain randomization techniques introducing controlled noise and variation to synthetic data
Challenge 5: Workflow Integration and Developer Experience
Building production multimodal applications remains prohibitively complex. Developers must orchestrate multiple models, manage state across modalities, handle failure modes gracefully, and optimize for cost/latency tradeoffs.
At our hackathon, the median time from idea to working prototype was 12-18 hours. Most of that time wasn't spent on novel algorithms—it was wrestling with API rate limits, debugging modality synchronization issues, and managing token budgets across pipeline stages.
Opportunities for builders:
- Declarative workflow orchestration where developers specify high-level goals and the system handles model selection, chunking strategies, and error recovery
- Automatic optimization profiling applications and suggesting latency/cost/quality tradeoffs
- Unified observability showing how information flows across modalities
Challenge 6: Cross-Modal Bias and Fairness
Multimodal models inherit biases from their training data, but cross-modal biases are harder to detect and mitigate. A model might associate certain accents with lower competence, or certain visual presentation styles with reduced credibility.
Opportunities for builders:
- Cross-modal bias detection identifying when combining modalities produces different outcomes than either alone
- Counterfactual testing tools swapping out individual modalities while holding others constant
- Auditing frameworks for multimodal systems that go beyond accuracy metrics
Part V: Hackathon Observations
On November 18, 2025, we co-hosted a multimodal hackathon with Google and Graphon AI at AGI House. Over 200 builders spent 18 hours exploring Gemini 3's native capabilities.
What We Observed
Cross-modal orchestration showed genuine coherence. The winner transformed literature into immersive experiences by coordinating text, visuals, video, and voice—each modality informing the others. Other teams built brand-to-video pipelines with semantic animation selection and knowledge graphs linking video timestamps to PDF pages to diagrams.
Vision-based interaction replaced traditional interfaces. Teams built touch-free shopping via hand gestures (<100ms latency), visual "conducting" of distributed audio, and design workflows where gestures triggered Figma deployments.
Real-time companions demonstrated conversational depth. Projects combining ultra-low latency voice with continuous visual analysis created systems detecting gestures, emotions, and attention while conversing. Challenge: maintaining <2s latency while processing multi-frame analysis.
Video-to-action translation became practical. Teams built workflow automation from screen recordings, assembly tutorials from static manuals, and podcast studios that "watch and listen" to sources.
Embodied applications showed data flywheel potential. Projects included crowd-sourced robotics training, real estate assessment via live video, and Alzheimer's research correlating mouse videos with neural activity.
Security emerged as immediate blocker. Second place built a layer scanning images/documents for prompt injection attacks—addressing that agentic systems create 10x larger attack surfaces.
Infrastructure dominated development time. Median prototype time was 12-18 hours, mostly spent on API orchestration rather than algorithms. Teams struggled with context limits (10-minute videos = 50K-100K tokens) and latency.
Conclusion
The multimodal inflection point isn't about better image generators or more capable chatbots. It's about systems that reason across modalities to enable new application categories: robots learning from human demonstration, creative tools iterating based on nuanced feedback, and enterprise agents processing messy real-world data reliably.
When 200+ builders independently converge on cross-modal reasoning and real-time generation as fundamental primitives, the opportunity is immediate, not speculative. Winners will understand both architectural foundations and real-world constraints, solving problems that compound value as foundation models improve rather than facing commoditization as capabilities democratize.
We're actively seeking teams positioned at these leverage points: native architectures, embodied data flywheels, prosumer workflow integration, and infrastructure enablement. The companies building these capabilities today, grounded in architectural advantages and real-world deployment constraints, will define the AI application layer for the next decade.
Acknowledgments
We're grateful to Google and Graphon AI for sponsoring the Gemini 3 Build Day and making this research possible. Special thanks to our speakers—Paige Bailey (AI Developer Relations Lead @ Google DeepMind), Bonnie Li (Research Scientist @ Google DeepMind), Cooper Price (Software Engineer @ Google Antigravity), Suyash Kumar (Senior Software Engineer @ Google), De Kai (Creator of Google Translate / Professor of Computer Science @ HKUST), Arbaaz Khan (CEO @ Graphon), and Div Garg (CEO @ AGI, Inc)—whose insights on infrastructure optimization, model safety, and architectural design informed both the event and this analysis. Our judges—Clark Zhang (CTO @ Graphon), Vaibhav Tulsyan (Research Engineer @ Google DeepMind), Audrey Choy (Senior Software Engineer @ Airbnb), and Yan Wu (Software Engineer @ Google Antigravity)—brought deep technical expertise across the AI stack, elevating project quality and identifying the most promising architectural approaches.
We extend our deepest gratitude to the entire AGI House community for creating a space where ambitious ideas meet execution. This hackathon brought together builders, researchers, and engineers who dedicated their day to pushing the boundaries of what multimodal AI can do—from clinical documentation systems to embodied AI agents to privacy-preserving data tools. Events like this don't just test technologies; they forge the communities and collaborations that will define the next era of intelligent systems.
And finally, thank you to Google's Nano Banana Pro for the graphics on this memo.
About the Authors

Jessica Chen
Research Lead, Primary Contributor

Amy Zhuang
Operations & Research, Contributor

Melissa Daniel
Investment Partner, Contributor

Alexa Orent
Operations Lead, Contributor

Rocky Yu
Founder and CEO, Contributor